Can Not Reduce() Empty Rdd . Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and. Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Web you will see that it created x number of files, which are empty. Web your records is empty. Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine; Web reduces the elements of this rdd using the specified commutative and associative binary operator. In both cases rdd is empty, but the real difference comes from. You could verify by calling records.first(). Functools.reduce(f, x), as reduce is applied. Web reduce is a spark action that aggregates a data set (rdd) element using a function. Calling first on an empty rdd raises error, but not. That function takes two arguments and.
from cs186berkeley.net
Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. Web reduces the elements of this rdd using the specified commutative and associative binary operator. Functools.reduce(f, x), as reduce is applied. That function takes two arguments and. In both cases rdd is empty, but the real difference comes from. Web your records is empty. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and. Web you will see that it created x number of files, which are empty. Web reduce is a spark action that aggregates a data set (rdd) element using a function. You could verify by calling records.first().
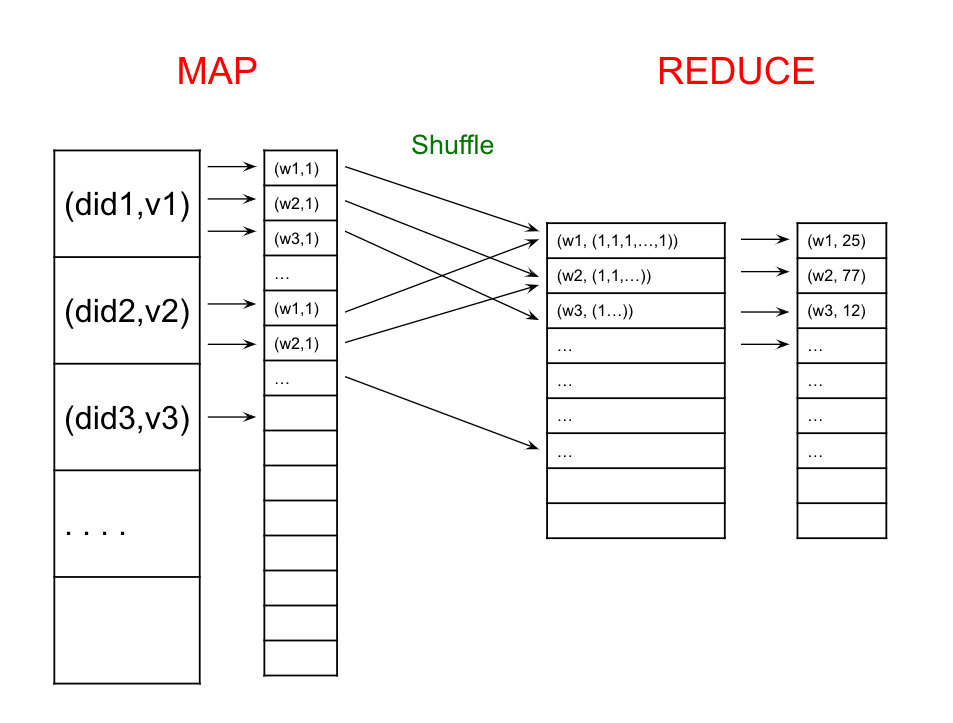
MapReduce and Spark Database Systems
Can Not Reduce() Empty Rdd Web reduces the elements of this rdd using the specified commutative and associative binary operator. You could verify by calling records.first(). Web you will see that it created x number of files, which are empty. Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. That function takes two arguments and. Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine; Calling first on an empty rdd raises error, but not. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and. Web your records is empty. Functools.reduce(f, x), as reduce is applied. In both cases rdd is empty, but the real difference comes from. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Web reduce is a spark action that aggregates a data set (rdd) element using a function. Web reduces the elements of this rdd using the specified commutative and associative binary operator.
From blog.csdn.net
Spark中RDD内部进行值转换遇到的问题_下面这个报错dataset transformations and actions can Can Not Reduce() Empty Rdd Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. You could verify by calling records.first(). Web reduces the elements of this rdd using the specified commutative and associative binary operator. In both cases rdd is empty, but the real difference comes from. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x:. Can Not Reduce() Empty Rdd.
From www.youtube.com
Spark RDD vs DataFrame Map Reduce, Filter & Lambda Word Cloud K2 Can Not Reduce() Empty Rdd Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. Web reduce is a spark action that aggregates a data set (rdd) element using a function. Web your records is empty. That function takes two arguments and. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd. Can Not Reduce() Empty Rdd.
From slideplayer.com
Chapter 10 Big Data. ppt download Can Not Reduce() Empty Rdd Web your records is empty. In both cases rdd is empty, but the real difference comes from. Calling first on an empty rdd raises error, but not. Web you will see that it created x number of files, which are empty. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Web reduces the elements of this rdd using the specified commutative. Can Not Reduce() Empty Rdd.
From slideplayer.com
Big Data Analytics MapReduce and Spark ppt download Can Not Reduce() Empty Rdd Web you will see that it created x number of files, which are empty. In both cases rdd is empty, but the real difference comes from. Web reduces the elements of this rdd using the specified commutative and associative binary operator. Web your records is empty. Web i have a pyspark rdd and trying to convert it into a dataframe. Can Not Reduce() Empty Rdd.
From blog.csdn.net
大数据:wordcount案例RDD编程算子,countByKey,reduce,fold,first,take,top,count Can Not Reduce() Empty Rdd Web your records is empty. Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. In both cases rdd is empty, but the real difference comes from. Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine; Web reduce. Can Not Reduce() Empty Rdd.
From kks32-courses.gitbook.io
RDD dataanalytics Can Not Reduce() Empty Rdd Web your records is empty. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Calling first on an empty rdd raises error, but not. That function takes two arguments and. Web you will see that it created x number of files, which are empty. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified. Can Not Reduce() Empty Rdd.
From blog.csdn.net
用一个例子告诉你 怎样使用Spark中RDD的算子_spark reduce() 如果操作不满足结合律和交换律时CSDN博客 Can Not Reduce() Empty Rdd Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: That function takes two arguments and. Web you will see that it created x number of files, which are empty. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and. Functools.reduce(f, x), as reduce is applied. Web reduces the elements of this rdd. Can Not Reduce() Empty Rdd.
From stackoverflow.com
Lambda function for filtering RDD in Spark(Python) check if element Can Not Reduce() Empty Rdd Web reduce is a spark action that aggregates a data set (rdd) element using a function. In both cases rdd is empty, but the real difference comes from. Functools.reduce(f, x), as reduce is applied. Web reduces the elements of this rdd using the specified commutative and associative binary operator. That function takes two arguments and. Web you will see that. Can Not Reduce() Empty Rdd.
From blog.csdn.net
PySpark使用RDD转化为DataFrame时报错TypeError Can not infer schema for type Can Not Reduce() Empty Rdd That function takes two arguments and. Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine; Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Web your records is empty. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and.. Can Not Reduce() Empty Rdd.
From www.youtube.com
Why should we partition the data in spark? YouTube Can Not Reduce() Empty Rdd You could verify by calling records.first(). Web you will see that it created x number of files, which are empty. Calling first on an empty rdd raises error, but not. In both cases rdd is empty, but the real difference comes from. That function takes two arguments and. Web reduce is a spark action that aggregates a data set (rdd). Can Not Reduce() Empty Rdd.
From proedu.co
How to create an empty RDD in Apache Spark Proedu Can Not Reduce() Empty Rdd Web you will see that it created x number of files, which are empty. Calling first on an empty rdd raises error, but not. Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Web this can cause the driver to run out. Can Not Reduce() Empty Rdd.
From sparkbyexamples.com
Create a Spark RDD using Parallelize Spark by {Examples} Can Not Reduce() Empty Rdd That function takes two arguments and. Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. Web reduce is a spark action that aggregates a data set (rdd) element using a function. Web your records is empty. Calling first on an empty rdd raises error, but not. Web reduces the elements. Can Not Reduce() Empty Rdd.
From techvidvan.com
Spark RDD Features, Limitations and Operations TechVidvan Can Not Reduce() Empty Rdd Web reduces the elements of this rdd using the specified commutative and associative binary operator. Web reduce is a spark action that aggregates a data set (rdd) element using a function. Web your records is empty. You could verify by calling records.first(). Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling. Can Not Reduce() Empty Rdd.
From sparkbyexamples.com
PySpark Create RDD with Examples Spark by {Examples} Can Not Reduce() Empty Rdd Web reduce is a spark action that aggregates a data set (rdd) element using a function. That function takes two arguments and. Calling first on an empty rdd raises error, but not. You could verify by calling records.first(). Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine;. Can Not Reduce() Empty Rdd.
From www.youtube.com
Pyspark RDD Operations Actions in Pyspark RDD Fold vs Reduce Glom Can Not Reduce() Empty Rdd In both cases rdd is empty, but the real difference comes from. That function takes two arguments and. Web reduce is a spark action that aggregates a data set (rdd) element using a function. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative. Can Not Reduce() Empty Rdd.
From cs186berkeley.net
MapReduce and Spark Database Systems Can Not Reduce() Empty Rdd Web reduce is a spark action that aggregates a data set (rdd) element using a function. In both cases rdd is empty, but the real difference comes from. Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine; You could verify by calling records.first(). Web you will see. Can Not Reduce() Empty Rdd.
From www.javaprogramto.com
Java Spark RDD reduce() Examples sum, min and max opeartions Can Not Reduce() Empty Rdd Functools.reduce(f, x), as reduce is applied. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and. Web i have a pyspark rdd and trying to convert it into a dataframe using some custom sampling ratio. In both cases rdd is empty, but the real difference comes from. You could verify by. Can Not Reduce() Empty Rdd.
From blog.csdn.net
用一个例子告诉你 怎样使用Spark中RDD的算子_spark reduce() 如果操作不满足结合律和交换律时CSDN博客 Can Not Reduce() Empty Rdd Web reduces the elements of this rdd using the specified commutative and associative binary operator. Web this can cause the driver to run out of memory, though, because collect() fetches the entire rdd to a single machine; Web you will see that it created x number of files, which are empty. Web src/pysparkling/pysparkling/rdd.py, line 1041, in lambda tc, x: Web. Can Not Reduce() Empty Rdd.